JPA
JPA를 사용하기 전 SQL 개발 문제점
- 개발자가 쿼리문을 하나하나 작성해야 한다.
- 객체지향 개발을 위해 DB 조작이 복잡하다.
- 객체 설계와 DB 간의 매핑 관계가 다르다.
-
객체 지향적으로 모델링할수록 매핑 작업만 늘어난다.
→ 객체를 자바 컬렉션처럼 DB에 저장할 수는 없을까? → JPA 등장
용어 설명
JPA
Java Persistence API 의 약자로 Java 의 ORM 을 제공해주는 API이다. JPA는 Java 객체와 데이터베이스 간의 매핑관계를 위해 다양한 인터페이스를 제공해주며 예시로는 @Entity, @Columns, @Id, @Table 등이 있다.
JPA는 표준명세 (*표준명세 = 인터페이스모음)
- 구현체: 하이버네이트, EclipseLink, DataNucleus
ORM이란?
Object Relation Mapping 의 악자로 객체지향 개념을 관계형 데이터 베이스모델에 매핑하여 사용할 수 있는 기술
JPA를 사용해야하는이유
- SQL 중심적인 개발에서 객체 중심으로 개발
-
생산성
저장: jpa.persistence(member) 조회: Member member=jpa.find(memberId) 수정: member.setName("변경할 이름") 삭제: jpa.remove(member) -
유지보수
-
패러다임의 불일치 해결
-
JPA와 상속
개발자: jpa.persistence(album); Jpa: 개발자 코드를 뒤에서 query문을 자동으로 생성해서 처리해준다. -
JPA와 연관관계
-
신뢰할 수 있는 엔티티,계층
-
-
성능
- 1차 캐시와 동일성 보장 ( ‘같은 데이터베이스 트랜잭션’ (조건) 안에서 SQL1번으로 두번의 조회를 할 수 있음 / 1차캐시는 데이터베이스 트랜잭션 단위로 짧은 캐시)
-
트랜잭션을 지원하는 쓰기 지연 (모아서 한번에)
transaction.begin() em.persist(memberA); em.persist(memberB); em.persist(memberC); -
지연로딩 (Lazy Loading)
- 지연로딩: 객체가 실제 사용될 때 로딩
- 즉시로딩: JOIN SQL로 한번에 연관된 객체까지 미리조회
→ 왜 중요한가? 최적화 (ex) 1차적으로 지연로딩으로 개발후 즉시로딩적용)
JPA 의 동작방식
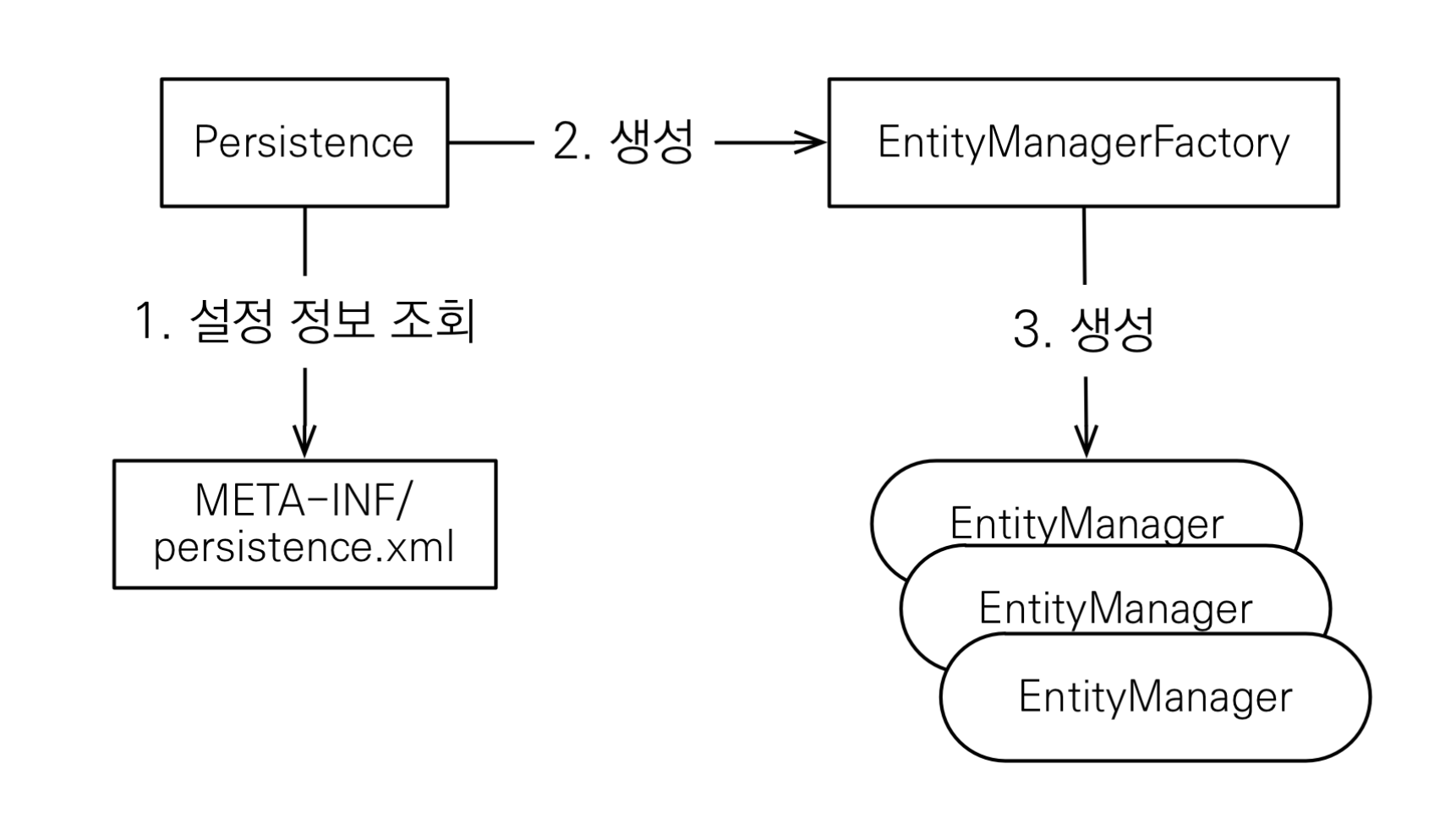
- Entity Class 작성
- JPA가 관리하는 객체, 데이터베이스 테이블과 매핑되는 객체
- EntityManager 생성
- EntityClass 와 데이터 베이스 간의 작업을 수행하는 역할 ( 역할 수행시 영속성 컨텍스트 사용)
- EntityManager는 일시적으로 생성되고 해제되는 방식
- Persistence Context
- EntityManager가 Entity 클래스와 데이터베이스 간 매핑을 처리할때 사용하는 컨텍스트
객체와 테이블 매핑 (ORM)
Entity:
- 객체와 테이블 매핑
- 데이터베이스 스키마 자동 생성
스키마 자동생성
- create: 시작시 기존 테이블 종료 후 생성, 개발 초기 단계에서 사용
- create-drop: 시작시 DB 생성 후 종료시 DB drop
- update: 개발 초기 단계에서 사용, 테스트 서버
- validate: 엔티티와 테이블이 정상 매핑되었는지 확인, 테스트 서버, 스테이징, 운영서버
-
none: 스테이징, 운영서버
enumerated validate 대신 테스트코드에서 이미 검증하고가서 마지막에 확인하는용도(?)